Building Sync and Batch AI Job Execution on Azure
The freelance brief for this project was to build an Azure-based execution layer for AI jobs that could support both immediate runs and queued batch processing. Some jobs needed to return a result while the user was still in the flow, while others could wait so the system could handle cost and throughput more efficiently.
The system had to support AI jobs in two modes:
- sync execution, where a job is dispatched immediately and completed as part of the active workflow
- batch execution, where jobs are queued, claimed into a batch window, submitted to a provider batch API, and written back when complete
I used the PDF summarization flow as the working use case to validate the path end to end. It gave the system a real input and output, while the important requirement stayed the same: the frontend and API should create jobs and expose status, n8n should orchestrate provider calls, PostgreSQL should store job state and results, and Terraform should deploy the Azure infrastructure in a repeatable way.
Before implementing the workflow, I mapped the state changes that every AI job would need. A sync job moves from created to processing to completed or failed. A batch job starts as queued work, gets claimed into a batch window, receives provider metadata, and then gets updated when the batch result is ingested. This helped me separate the responsibilities clearly before building the services.
The app owns the product-facing layer: authentication, profile selection, job creation, job history, result viewing, admin visibility, and internal APIs. It also owns the durable state boundaries, so every job has a clear record in PostgreSQL and can be inspected after execution. n8n owns the orchestration layer: It receives a job from the app, follows the correct execution branch, calls the AI provider, and writes the result back through the application’s internal APIs. This kept provider logic and long-running workflow behavior out of the web app, while still keeping the app as the source of truth for job state.
To keep the execution flow general, I used a profile-driven contract between the app and n8n. A profile defines which fields are needed for a run, which values are allowed, which webhook should be called, and how the request payload should be mapped before it reaches n8n. That means a new AI job type can reuse the same app structure as long as it defines the required inputs and webhook mapping.
For the included example, the active profile exposes:
executionMode:syncorbatchbatchStrategy: currentlycount_only- a runtime webhook path
- payload mappings for the job, user, input, execution mode, and batch strategy
With that profile layer in place, the UI, API validation, and n8n payload all follow the same contract instead of each layer inventing its own request shape. This made both execution paths easier to test because the request structure stayed consistent from the frontend to the workflow.
For sync execution, the app creates a job as soon as the user starts a run and sends it to n8n immediately. The workflow marks the job as processing, prepares the provider request, executes the AI call, writes the result into PostgreSQL, and marks the job as completed. This path is useful when the user expects a result during the same interaction.
For batch execution, the app first creates queued work instead of sending every job straight to the provider. n8n selects candidates, while the backend handles the important state change by atomically opening a batch window through /api/internal/batches/open. That prevents two workflow runs from claiming the same queued jobs. If there are not enough jobs for the configured MAX_BATCH_SIZE, the flow exits cleanly and waits for more work. If a batch window is ready, n8n creates the provider batch, stores the provider metadata, polls for completion, and persists each returned result against the correct job ID. Keeping the batch claim in backend transaction logic was useful because a delayed response alone would not solve batch processing. The system still needs ownership, correlation, polling, ingestion, and clear state transitions, otherwise it becomes easy to lose track of which provider result belongs to which application job.
On the database side, the application tables follow the same execution model by storing users, jobs, results, batch windows, batch items, benchmark runs, and provider metadata such as model, token usage, latency, and estimated cost. n8n keeps its own runtime metadata separately in n8ndb, which kept application state readable without fighting how n8n manages workflow data.
I also included cost tracking so sync and batch jobs can use different pricing inputs, and the estimated cost can reflect the actual execution path. This matters because batch execution only makes sense when the system can show the tradeoff: slower completion in exchange for better cost and throughput behavior. The admin view helped validate this during testing because it shows jobs, batch windows, queue state, benchmark runs, latency, and cost metrics in one place.
For local testing, Docker Compose runs the app, PostgreSQL, and n8n together, which made it possible to test the sync path, batch path, profile payloads, database writes, and workflow activation without cloud deployment noise. Once the execution behavior was stable locally, Terraform handled the Azure deployment by provisioning the Resource Group, Log Analytics, Azure Container Registry, Container Apps, Key Vault, PostgreSQL Flexible Server, Storage Account, private Blob container, managed identity, and RBAC assignments.
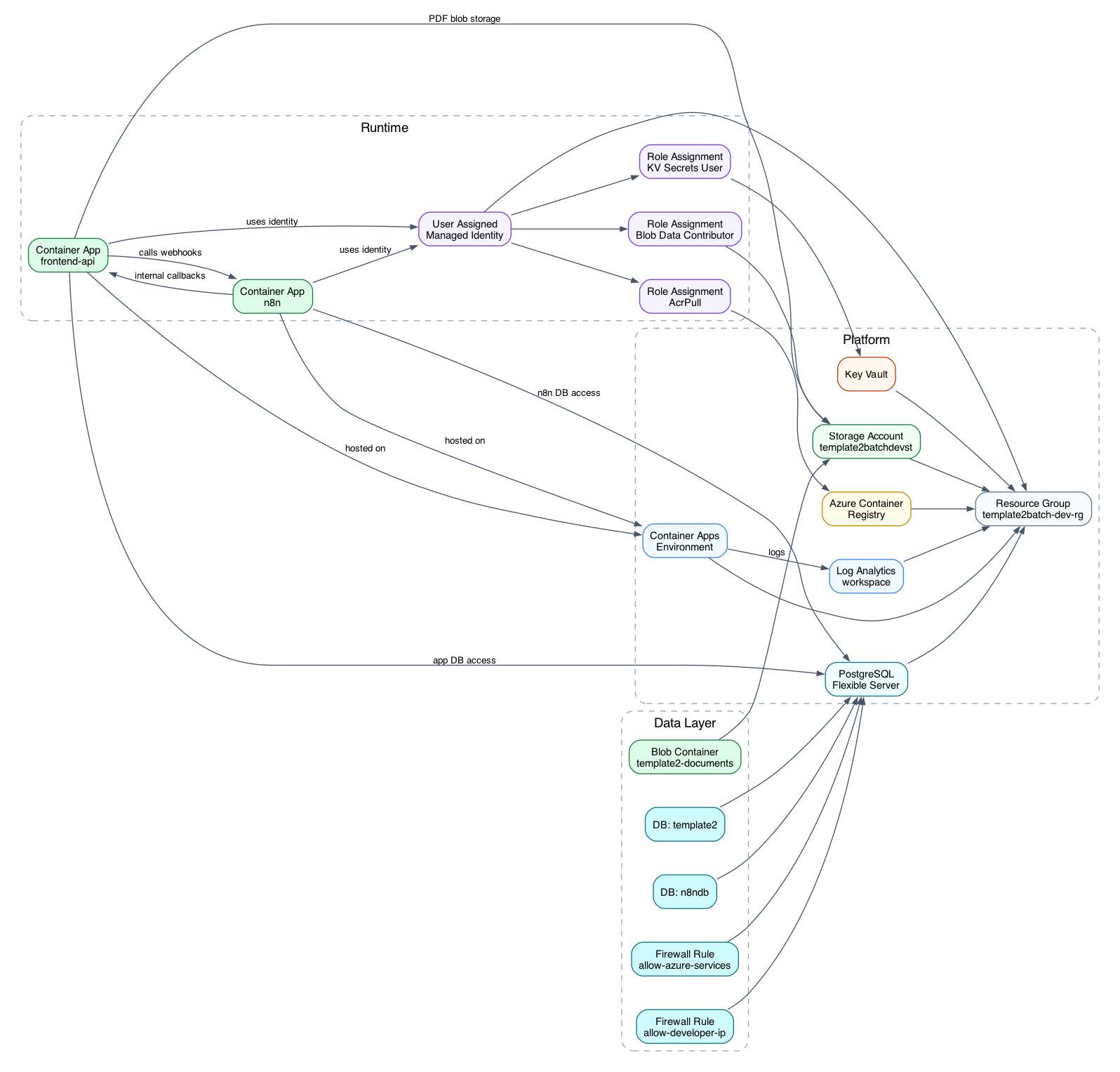
Figure 1. Azure infrastructure for sync and batch AI job execution.
The final system gives AI jobs a clear execution model:
- use sync when the result is needed immediately
- use batch when the work can wait and cost or throughput matters more
- keep job state and results durable in PostgreSQL
- keep orchestration inside n8n
- provision the cloud runtime with Terraform
What I value most about this project is that it separated the execution pattern from the example use case. The PDF summarization flow proves the system end to end, but the reusable part is the structure behind it: a cloud-ready way to run AI jobs either immediately or in controlled batches without changing the whole application every time the use case changes.
Project repository: malladi2610/Cloud_infra_project